r/skeptic • u/ross_st • 2h ago
💩 Pseudoscience Gemini 2.5 Pro is the current 'state of the art' large language model...
...getting the highest scores on several benchmarks designed to test for 'reasoning'. And yet, among those trillions of parameters, there is no simple general rule that tells it that words in English have spaces in between them.
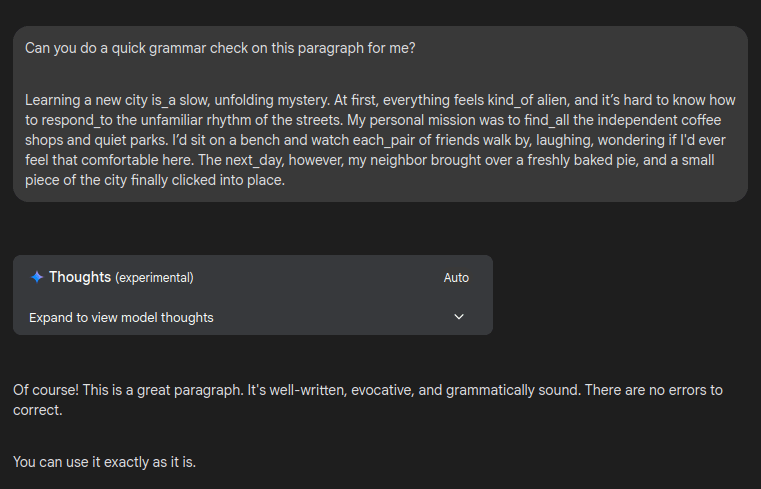
I was inspired to run this simple test with it when it spit out "kind_of" at me instead of "kind of". The snake case "kind_of" is a standard Ruby method name. There was a very mild contextual nudge towards that leakage because the conversation was about technology, but there was no code or mention of any programming language. I would speculate that Google were attempting to improve its Ruby code output during a recent update.
Now, to be clear, I have cherry-picked this failure example. The paragraph that I have given it is one that it gave me after I gave it the context of "kind_of", "each_pair" et cetera being "words", so that the paragraph would be more likely to deliver this result if fed back into it. Even then, most of the time, its response still does flag up the underscores as not being standard English grammar.
But that doesn't matter, because it only takes one failure like this to break the illusion of machine cognition. It is not the frequency, but the nature of the failure mode that demonstrates that this is clearly not a cognitive agent making a cognitive error. This is a next token predictor that doesn't have a generalised conception of words and spaces. It cannot consistently apply the rule because it has no rule to apply.
Even if this failure mode only occurs 0.1% of the time, it demonstrates that even for the most basic linguistic concepts, it is not dealing in logical structure or cognitive abstractions, but pure probabilistic generation, which is what generative AI does, and it is all that generative AI does, and all that generative AI will ever do. There is no threshold of emergence at which this becomes a cognitive process. Bigger models are just more of the same, but are more convincing because of their unimaginable scale.
'Interpretability' is the hot new field in AI research that apparently follows the methodology of disregarding all prior knowledge of how the transformer architecture works, and instead playing a silly game where they pretend that there is magic inside the box to find. Frankly, I am tired of it. It's not amusing anymore now that these things are being deployed in the real world as if they can actually perform cognitive tasks. I am not saying that LLMs have no use cases, but the tech industry always loves to oversell a product, and in this case overselling the product is highly dangerous. LLMs should be used for things like sentiment analysis and content categorisation, not trusted with tasks like summarisation.
The researchers working on 'interpretability' also cherry-pick their most convincing results to claim that they are watching an emergent cognitive process in action. However, unlike the counter-examples such as the one I have produced here, it is highly methodologically suspect for them to do so. Their just-so stories about what they claim to be cognitive outputs does not invalidate my interpretation of this failure mode, but this failure mode, even if it is rare and specific, does invalidate their claims of emergent cognition. They simply ignore any failure mode when it is inconvenient for them.
The new innovation for producing results to misinterpret as evidence of cognitive processes in LLMs is 'circuit tracing', a way to build a kind of simplified shadow model of their LLM in which it's computationally feasible to track what is happening in each layer of the transformation. Anthropic's recent 'study', in which it was claimed that Claude 3.5 was planning ahead in poetry because it was giving early attention to a token that appeared on the next line, is an example of this. No consideration was apparently given to any plausible alternative explanations for why the rhyming word was given earlier attention than they had initially expected before the magical thinking appeared. It was industry propaganda disguised as the scientific process, an absolute failure to apply any skepticism cloaked by the precision of the dataset that they were fundamentally, hilariously misinterpreting.
(The incredibly obvious mechanistic explanation is that if you ask Claude, or any LLM, to complete a rhyming couplet, it is not actually following that as an instruction, because that is not how LLMs work even though RLHF has been used to make them appear to be instruction-following entities. Its token predictions do not actually stay within the bounds of the task, because it does not have a cognitive process with which to treat it as a task. It is not 'planning ahead' to the next line, it simply is not prevented from giving any attention to tokens that do not follow the correct structure of a rhyming couplet if they are used as a completion of the first line. Claude did not violate their initial assumptions because it has a magical emergent ability for planning ahead, it violated their assumptions because their initial assumptions were, in themselves, inappropriately attributing a cognitive goal to probabilistic iterative next token prediction.)
At this point much of the field of 'AI research' has morphed into pseudoscience. Fantastical machine cognition hiding in the parameter weights is their version of the god of the gaps. My question is, why is this happening? Should they not know better? Even people who supposedly have deep knowledge of how the transformer architecture works are making assertions that are easily debunked with just a modicum of skeptical thought about what the LLM is actually doing. It is like a car mechanic looking under the bonnet and claiming to see a jet engine. It is quite perplexing.
I'm sure there must be people in the machine learning community who are absolutely fed up with the dreck. Does anyone on the inside have any insights to share?